

+
- 21-10-2024
- Julien M'Barki
Recherche
Musique
Éthique du numérique
Recherche
Musique
Éthique du numérique
Expliquer la recommandation algorithmique de musique : quels effets sur les usagers ?
Une analyse expérimentale des changements de comportements de découverte musicale lorsqu'on explique le fonctionnement de la recommandation par algorithme.
Le volume d’œuvres disponibles sur les services de streaming musical a stimulé le besoin généralisé de recommandations de contenus visant à réduire les coûts de recherche des utilisateurs.1 La recommandation personnalisée sur les plateformes de streaming prend principalement la forme de recommandations algorithmiques dérivées des préférences et de l’historique de l'utilisateur, communément appelées Music Recommender Systems (MRS).
Cette étude2 a été co-réalisée avec Mehdi Louafi (université d’Orléans), et s’inscrit dans la continuité des travaux de la Chaire PcEn sur la "découvrabilité" des œuvres sur les services en ligne.3 Les dispositifs de recommandation sont l'une des clés de la découvrabilité d'un contenu par l'utilisateur. Ils participent à le visibiliser, à le mettre en avant sur l'interface, au sein de l'océan de l'offre proposée. Ces dispositifs de recommandation ne présagent cependant pas des comportements réels des usagers et n'influencent pas automatiquement la demande. Les usages de la recommandation sont un point mal documenté et la question reste posée de l'écart entre la mise en avant et la consommation réelle. C'est pourquoi, dans cette étude nous avons cherché à appréhender, au-delà de la découvrabilité de l'offre sur l'interface, les comportements de découverte de l'usager.
Par ailleurs, l’utilisation croissante d’algorithmes pour déléguer des tâches dans diverses facettes de nos vies a renouvelé les discussions sur l’autonomie, la liberté et les processus de décision des utilisateurs. Une abondante littérature sur l’IA explicable (XAI)4 s'est développée afin d'améliorer la compréhension des décisions des systèmes d’IA pour les experts et les utilisateurs finaux. Notre étude s’inspire de la littérature sur l’XAI en l'appliquant à l’influence de l’explication de la fonctionnalité d’un système de recommandation musicale sur la consommation.
La question principale à laquelle nous cherchons à répondre est celle de savoir si l'explication, aux auditeurs, du système de recommandation qui leur est proposé, joue un rôle sur leur comportement de découverte musicale.
Méthodologie
Pour répondre à cette question, nous avons mis en place un protocole expérimental au sein du Laboratoire d’Économie Expérimentale de Paris.5 Les sessions d'expérience auprès de participants volontaires ont eu lieu entre le 6 juin et le 5 juillet 2024.
Afin de pouvoir mesurer les effets de l'explication, l'ensemble des participants a été réparti aléatoirement en trois groupes :
- Un groupe de contrôle qui ne reçoit aucune explication sur le processus de recommandation, (groupe "Algorithme").
- Un groupe de contrôle qui ne reçoit aucune explication sur le processus de recommandation et des recommandations basées sur l’inverse de ses préférences (groupe "Anti-Algorithme").
- Un groupe de traitement qui reçoit des explications sur le processus de recommandation (groupe "Explications").
Dans un premier temps, les participants ont rempli un questionnaire retraçant à la fois leurs caractéristiques socio-démographiques et leurs préférences musicales.
L'expérience a ensuite consisté en une tâche de décision d'écoute d'une durée de 20 minutes durant laquelle les participants ont reçu un ensemble de recommandations générées par un algorithme simplifié (réalisé par nos soins) basé sur les réponses au questionnaire sur leurs préférences musicales. Au cours de la tâche de décision d’écoute, les participants interagissent avec les morceaux de musique recommandés.
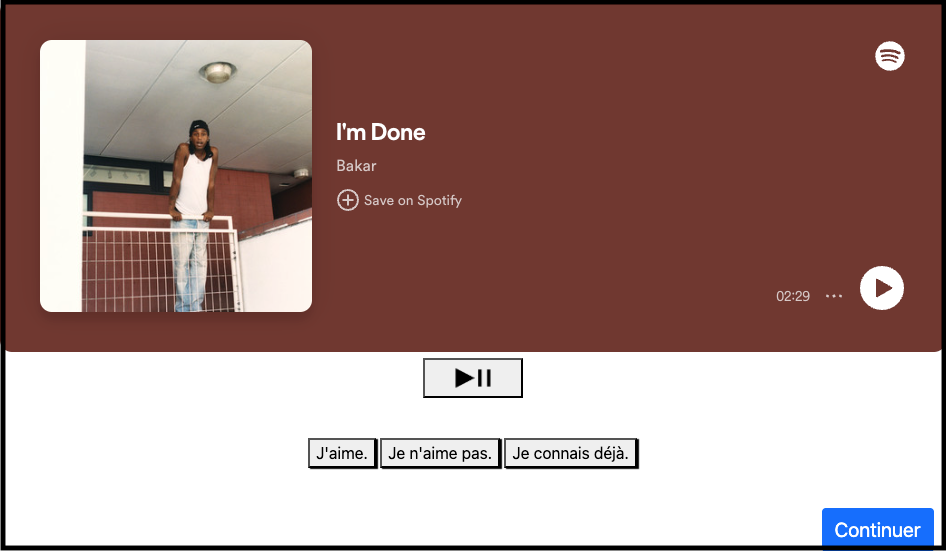
Au début de chaque écoute, les participants reçoivent les caractéristiques principales (titre, artiste, image de couverture et durée) des morceaux recommandés via un affichage intégré de l’interface Spotify dans notre interface de décision (voir Figure 1). Afin de se concentrer sur l'aspect "découverte" de leurs comportements, il est demandé aux participants d’indiquer s’ils connaissent déjà les morceaux recommandés (via le bouton "je connais déjà"), puis nous excluons ces morceaux de l'analyse.
Pour les morceaux que les participants découvrent, nous mesurons le temps d'écoute relatif de chaque morceau au cours de la tâche ce qui nous permet de distinguer deux comportements :
- "L'étude" lorsque les participants choisissent d'écouter un morceau longuement, pendant une durée autodéterminée ce qui correspond à une découverte approfondie.
- "L'exploration" (ou le "zapping") lorsque les participants choisissent de passer rapidement au morceau recommandé suivant.
Une fonctionnalité implémentée permet également aux participants d'exprimer leurs préférences via des boutons "J'aime" et "Je n'aime pas" ("like/dislike"), offrant ainsi un moyen de signifier leur inclination envers les morceaux qu'ils trouvent (ou non) attrayants.
Les préférences exprimées par les "likes" ainsi que les comportements de découverte approfondie ("étude") relèvent tous deux ce que nous nommons "l'engagement" d'un auditeur pour un morceau.
Enfin, à la fin de la tâche d'écoute, nous avons interrogé les participants pour savoir quelles étaient leurs connaissances finales sur l'algorithme c’est-à-dire ce qu'ils avaient compris des explications fournies.
Les participants
Au total, 364 participants ont terminé l’expérience, répartis sur 22 sessions expérimentales, qui ont duré au total en moyenne 40 minutes. En moyenne, les participants à l’étude avaient 41 ans, avec une majorité de femmes, représentant 64,01 % de l’échantillon. Le niveau d’études variait : 31,32 % étaient titulaires d’un Master, 39,28 % d’une Licence ou d’un DUT et 25,55 % d’un baccalauréat. Les étudiants étaient le groupe le plus représenté (26,92 %), suivis par les employés (24,17 %), les cadres et ouvriers qualifiés (14,56 %), les professions intermédiaires (8,52 %), les autres professions (7,42 %), et les artisans, commerçants et chefs d’entreprise (4,12 %).
Les participants ont été aléatoirement répartis ainsi dans les trois groupes :
- 133 participants ont été placé dans la condition "Explications" (36,54 %).
- 113 dans la condition "Algorithme" (31,04 %).
- 118 dans la condition "Anti-Algorithme" (32,42 %).
En moyenne, les participants ont écouté 37,59 morceaux chacun pendant la décision d'écoute, et en connaissaient 4,77, ce qui donne un taux de connaissance de 12,68 %. Au total, l’ensemble des participants a écouté 13 685 morceaux, dont 1 739 étaient connus, ce qui donne un nombre final d'observations de 11 946 morceaux dans notre échantillon de données.
L'impact de l'explication se renforce lorsque les participants y consacrent du temps
A caractéristiques socio-démographiques équivalentes, l'explication n'affecte pas, en moyenne, le temps d'écoute relatif de chaque morceau par les participants (et donc leur choix entre comportement d'étude ou d'exploration); ce temps est statistiquement non-significatif (Annexe 1).
Au-delà de cette absence d'effet moyen sur l’ensemble des participants du groupe "Explications", nous relevons qu'un grand nombre de participants a passé moins de 50 secondes sur la page d'explication. Les statistiques descriptives révèlent que les participants ont passé en moyenne 34 secondes à lire les explications sur l'algorithme.
C'est pourquoi nous avons créé une variable catégorielle au sein des participants selon le temps passé à lire les explications (soit l'intensité du traitement) :
- Non (groupes non-traités).
- Faible (≤ 16,25 secondes).
- Moyen-Faible (> 16,25 et ≤ 27 secondes).
- Moyen-Élevé (> 27 et ≤ 43,75 secondes).
- Élevé (> 43,75 secondes).
Plus les auditeurs passent du temps à lire les explications, plus leur comportement de découverte approfondie ("étude") se renforce
En prenant en compte cette variable, les effets de l'explication sur la durée d'écoute du morceau deviennent significatifs (Annexe 2) :
- Le groupe de traitement Élevé a passé presque deux fois plus de temps (renforcement du comportement de découverte approfondie) à écouter les morceaux dans les premières recommandations, par rapport aux autres niveaux d'intensité de traitement et aux groupes de contrôle.
- Les groupes de traitement à intensité Faible, Moyen-Faible et Moyen-Élevé ont montré un temps d'écoute relatif inférieur à celui des groupes non traités. Par ailleurs, la catégorie Faible renforce son comportement "d'exploration" par rapport aux autres groupes, traités ou non.
Des compréhensions similaires de l'algorithme peuvent s'accompagner de comportements d'écoute différents
Au-delà du temps passé, une autre variable doit être examinée, celle de la compréhension réelle des explications proposées. La Figure 2 montre les connaissances finales acquises sur l'algorithme.
La catégorie Faible qui a passé le moins de temps à lire les explications a, comme cela était prévisible, un niveau de connaissance faible au terme du processus (non différent de celui des groupes non-traités).
Les catégories Moyen et Élevé partagent le même niveau de compréhension de l'algorithme mais leurs comportements d'écoute sont différents. En effet, seule la catégorie Élevé est affectée sur ses comportements par les explications. On peut en conclure, qu’avec des compréhensions similaires, les explications n’ont pas les mêmes effets sur les comportements d'écoute selon les groupes.
Des compréhensions similaires de l'algorithme peuvent s'accompagner de différences dans l'appréciation des morceaux
La même conclusion peut être tirée en matière de goûts et aversions (Annexe 3) des participants pour les morceaux recommandés (mesuré par la fonction "like/dislike") :
- Les participants de la catégorie Élevé ont des chances d’aimer un morceau recommandé ("like") d’environ 21,05 % supérieures à celles du groupe "Algorithme" et de 18,29 % supérieures à celles du groupe "Anti-Algorithme".
- A l'inverse, les participants de la catégorie d’intensité Élevé ont 23,66 % de chances en moins de ne pas aimer un morceau recommandé ("dislike") par rapport aux participants de la condition Algorithme et 14,36 % par rapport à la condition "Anti-Algorithme".
- Les explications pour les catégories Moyennes (Moyen-Faible et Moyen-Élevé) n'ont pas d'effets visibles sur leurs comportements d'écoute et pas non plus sur leur appréciation des morceaux.
La compréhension de l'algorithme de recommandation ne suffit donc pas à changer les comportements d'écoute. La variable qui joue le plus est celle du temps passé, qui, à son tour, peut influer sur la compréhension.
On constate ainsi un engagement (incluant à la fois temps d’écoute et appréciation du morceau) supérieur pour les personnes appartenant à la catégorie Élevé c’est-à-dire celles qui ont passé le plus de temps à lire les explications.
Des profils différenciés selon les connaissances en informatique et la perception générale du streaming et de la recommandation
L'intensité du traitement (c’est-à-dire le temps passé à lire les explications) étant le principal vecteur de différenciation de l'effet du traitement, d'une part en termes de compréhension de l'algorithme, d'autre part en termes de changement de comportement d'écoute musicale, il parait intéressant d'observer les caractéristiques des personnes qui composent les divers groupes.
Nous observons deux résultats principaux :
- Les personnes les moins impliquées dans les explications (catégorie Faible), sont celles qui déclarent avoir le meilleur niveau de connaissances en informatique et/ou technologies d’information. Ce résultat semble indiquer que les explications ne pourraient avoir d’effet que sur les personnes conscientes d'en avoir besoin et qui, par conséquent, passent du temps à lire et comprendre les explications.
- La catégorie Élevé déclare avoir eu une recommandation de morceaux de meilleure qualité que les catégories Moyen. En d’autres termes, le premier groupe a trouvé que les morceaux recommandés par notre algorithme correspondaient mieux à ses préférences.
Enfin, des résultats moins significatifs montrent un effet différencié possible en fonction du genre des participants et de leur opinion préalable sur les plateformes de streaming.
Ces différentes caractéristiques montrent que les effets des explications diffèrent en fonction de la personne qui les reçoit, et ouvrent la voie à des recherches futures sur les profils d'utilisateurs qui pourraient bénéficier le plus d'une explication sur la recommandation algorithmique proposée par un service (Figure 3).
- Ne comprend pas - Ne s'engage pas
- Ne comprend pas comment la recommendation est effectuée
- Pas de différence d'engagement (temps d'écoute) avec les groupes non-traités
- Pas de différence d'engagement ("likes") avec les groupes non-traités
- Plus de connaissances en informatique que les autres groupes
- Comprend - Ne s'engage pas
- Comprend comment la recommandation est effectuée
- Pas de différence d'engagement (temps d'écoute) avec les groupes non-traités
- Pas de différence d'engagement ("likes") avec les groupes non-traités
- Groupe plus masculin que les autres groupes
- Comprend - S'engage
- Comprend comment la recommandation est effectuée
- Différence d'engagement (temps d'écoute) avec les groupes non-traités
- Différence d'engagement ("likes") avec les groupes non-traités
- Meilleure opinion générale sur le streaming que les autres groupes
Implications pour les acteurs de la filière
Cette étude a pour but d’observer les différences de comportements de découverte des usagers, engendrées par l’explication de la recommandation par algorithme. Notre protocole expérimental a permis d’observer les comportements (étude, appréciation) pour des morceaux inconnus au préalable des participants.
Pour le groupe qui a passé le plus de temps à la lecture des explications (Figure 3), les comportements d'engagement dans l'écoute prédominent : ce groupe privilégie l'étude c’est-à-dire la découverte approfondie des morceaux et apprécie plus que les autres groupes, les morceaux recommandés. Pour ce groupe, une généralisation des explications du processus de recommandation pourrait avoir d'importantes répercussions sur l'ensemble des acteurs de la filière musicale :
- Les régulateurs se sont saisis de la question de la transparence et de l'explicabilité notamment par l' "IA Act"6 récemment adopté. Notre étude montre que des explications peuvent favoriser la découverte approfondie de morceaux jusque là inconnus et que le régulateur pourrait s’emparer de ce levier pour favoriser la diversité culturelle, non plus seulement de l’offre, mais dans ce cas, de la demande.
- Pour les artistes et les maisons de disques, le gain d'engagement grâce à l'explication peut être bénéfique pour créer de nouvelles bases de fans, par la découverte d'œuvres inconnues.
- Pour les distributeurs, l'effet pourrait être visible en deux temps. A court terme, l'explication, en valorisant la découverte approfondie, limite le nombre d'artistes du catalogue d'un même distributeur auxquels l'usager accorde du temps d'écoute et par conséquent les rémunérations afférentes. A long terme cependant, l'engagement accru envers des artistes peut se révéler bénéfique pour le distributeur en incitant les usagers à attendre les futures sorties de ces artistes avec impatience.
- Pour les plateformes de streaming, l'effet peut être différent selon le modèle de répartition des droits adopté.7 Dans le modèle market centric, la plateforme distribuerait moins de rémunérations aux détenteurs de droits, car pour une même durée d'écoute, les utilisateurs - ceux du groupe Elevé qui bénéficient des explications et s'engagent - écouteraient moins d'artistes différents. Dans le modèle user centric, au contraire, la plateforme distribuerait plus de rémunérations aux ayants droit, car les utilisateurs s'ils écoutent moins d'artistes, le feraient de manière plus régulière.
Lien vers l’article complet : https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4982393
Annexes disponibles ici : Lien
Notes
- ↑
Voir : Bakos, J. Y. (1997). Reducing buyer search costs: Implications for electronic marketplaces. Management science, 43 (12), 1676–1692. ; Farchy, J., Méadel, C., & Anciaux, A. (2017). Une question de comportement. Recommandation des contenus audiovisuels et transformations numériques. Tic&société, 10 (2-3), 168–198. ; Moreau, F., & Wikström, P. (2024). The Impact of Algorithmic and Human Recommendations on Platform User Satisfaction.
- ↑
Lien vers l’article de recherche complet : Louafi, M., & M’Barki, J. (2024). Algo-Rhythm Unplugged: Effects of Explaining Algorithmic Recommendations on Music Discovery. http://dx.doi.org/10.2139/ssrn.4982393
- ↑
Voir : Farchy, J., Bideau, G., & Tallec, S. (2022). Deux ou trois choses que nous savons sur les dispositifs de recommandation. Chaire PcEn.
- ↑
Voir : Castelvecchi, D. (2016). Can we open the black box of ai? Nature, 538 (7623), 20–23. ; Adadi, A., & Berrada, M. (2018). Peeking inside the black-box: a survey on explainable artificial intelligence (xai). IEEE access, 6, 52138–52160. ; Afchar, D., Melchiorre, A., Schedl, M., Hennequin, R., Epure, E., & Moussallam, M. (2022). Explainability in music recommender systems. AI Magazine, 43 (2), 190–208.
- ↑
- ↑
- ↑
Voir : Moreau, F., Wikström, P., Haampland, O., & Johannessen, R. (2024). Alternative payment models in the music streaming market: A comparative approach based on stream-level data. Information Economics and Policy, 68, 101103.